
Author: Björn Dick, High Performance Computing Center Stuttgart - HLRS
Besides scalability, resiliency and I/O, the energy demand of HPC systems is a further obstacle on the path to exascale computing and hence also addressed by the ExaFLOW project. This is due to the fact that already the energy demand of current systems accounts for several million € per year. Furthermore, the infrastructure to provide such amounts of electric energy is expensive and not available at the centers these days. Last but not least, almost the entire electric energy is transferred to thermal energy, posing challenges with respect to heat dissipation.
As known from other studies1, CPUs account for the major fraction of energy. However, if the CPU’s clock frequency can be reduced, a lower supply voltage is sufficient which (due to Ohm’s law) implies a reduced leakage current and hence energy savings. At the same time, properties of algorithms and available hardware often give rise to situations where CPUs have to wait for the memory subsystem to deliver data. In order to save energy, it is hence a reasonable approach to throttle the CPU’s clock frequency. By doing so, energy may be saved while only slightly reducing performance since the CPU anyway has to wait for the memory subsystem most of the time.
However, this so called memory boundness can vary between phases of a simulation, in particular between the actual computation, communication of partial results and writing of results to disk. We hence implemented a mechanism in Nektar++ to measure the energy and runtime demand of those phases. By utilizing this mechanism and running a simulation with all available clock frequencies (fixed within the respective run), we were able to figure out corresponding energy and runtime demands. Furthermore, we varied the degree of parallelism as well as the I/O strategy (single large HDF5 file vs. many small XML files). All of this has been done with our industrial automotive use case.
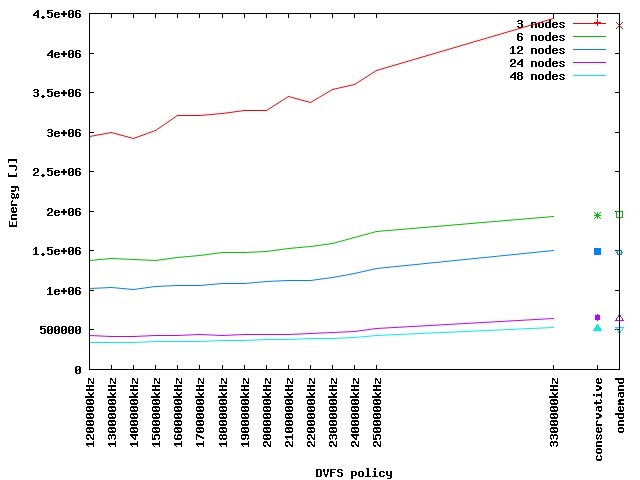
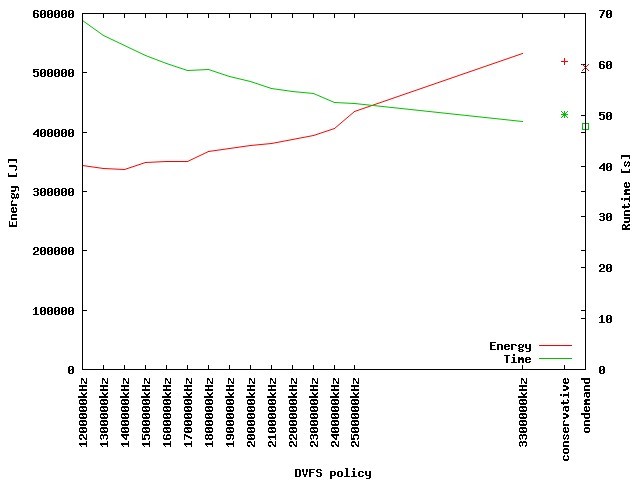
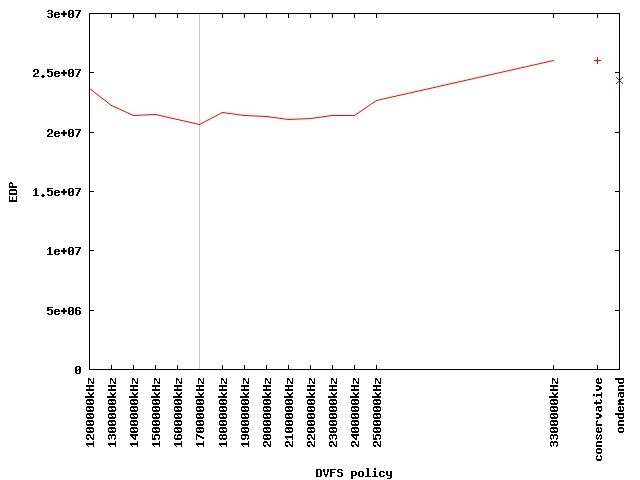
Figure 1 depicts the energy demand of the actual computation phase for different degrees of parallelism and clock frequencies. Obviously, employing as much parallelism as possible is optimal within the examined range. Hence, Figure 2 shows the energy and runtime demand of the 48 nodes case in detail. Fortunately, the energy demand drops faster when compared to the increase of runtime. Nevertheless, one has to balance energy vs. runtime here. The energy-delay-product (EDP) is a widely used metric to do so. By assessing the product of energy and runtime demand, an increase of both shows up in the metric so that a fair optimum can be found by minimizing EDP. As depicted in Figure 3, this optimum turns out to be 1.7GHz with respect to the actual computation phase. Deploying this clock frequency reduces the energy demand by 19.2% compared to the default setting of 2.5GHz while increasing the runtime by 12.6%. If compared to turbo mode (depicted as 3300000 kHz), energy savings of 34% are possible while increasing the runtime by 20%.
 |
 |
|
Figure 1: Energy demand of actual computation phase for different degrees of parallelism and clock frequencies |
Figure 2: Energy and runtime demand of actual computation phase for different clock frequencies |
 |
|
Figure 3: Energy-Delay-Product of actual computation phase for different clock frequencies |
Throttling the clock frequency in the halo exchange phase turned out to be not beneficial since the increase of runtime outweighs the respective energy savings. However, in contrast to this, one would expect a substantial energy saving potential in this phase since processes have to wait for synchronization. We hence plan to further investigate this.
When doing I/O with the XML strategy, a minimal amount of parallelism is optimal. However, there is an increase of runtime when doing so. Regarding the optimal clock frequency, the same holds as for the halo exchange phase.
When switching to HDF5 output, the results remain almost the same, except that the optimal degree of parallelism turns out to be 12 nodes here. Furthermore, the optimal clock frequency is 1.7GHz.
However, all the measurements turned out to be very noisy so that further investigations are required in order to assure the results.
Overall, using an appropriate amount of parallelism (and hence doing the calculations as fast as possible) seems to be much more crucial with respect to energy efficiency than using a proper clock frequency.
If, after tackling the above mentioned issues, the halo exchange and I/O phases are going to exhibit optimal clock frequencies which significantly differ from that of the actual computation phase, we will try to implement a mechanism to dynamically adapt the clock frequency in order to lower the application's energy footprint while (almost) preserving runtimes.
1Khabi D., Küster U. (2013) Power Consumption of Kernel Operations. In: Resch M., Bez W., Focht E., Kobayashi H., Kovalenko Y. (eds) Sustained Simulation Performance 2013. Springer

