
Author: Allan S. Nielsen, Ecole polytechnique fédérale de Lausanne (EPFL)
HPC resilience is expected to be a major challenge for future Exascale systems. On todays Peta scale systems, hardware failures that disturb the cluster work flow is already a daily occurrence. The currently used most common approach for safe-guarding applications against the impact of hardware failure is to write all relevant data on the parallel file system at regular intervals. In the event of a failure, one may simply restart the application from the most recent checkpoint rather than recomputing everything again. This approach works fairly well for smaller applications using 1-100 nodes, but becomes very inefficient for large scale computations for various reasons. A major challenge is that the parallel file system is unable to create checkpoints fast enough. It has been suggested that if one were to use the current checkpoint-recover from parallel file system approach on future Exascale systems, applications would be unable to make progress due to being in a constant state of checkpointing to, or restarting from, the parallel file system.
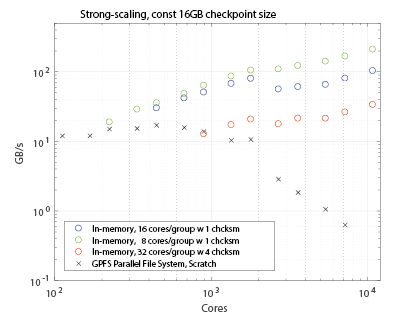
In a previous blog post we outlined an alternative approach to protecting data. The content of arrays distributed across nodes may be protected by encoding parity data and storing it locally in-memory. Doing so, the data may be recovered so long as the number of nodes lost is smaller than the number of parity blocks computed. This approach to protecting the data is scalable as the encoding-decoding procedure may be performed locally with-in groups of ranks. In figure 1, the bandwidth of data protected as a function of cores is presented as measured when encoding a small 16GB array distributed equally accross nodes on the EPFL Fidis cluster using the checkpoint library. The key thing to notice here is how when using several thousand cores, creating an in-memory checkpoint is up to two orders of magnitude faster than creating a checkpoint on the parallel file system.
The pcheckpoint library uses MPI to efficiently encode and decode distributed arrays using arbitrary group size with an arbitrary number of parity blocks. As such, with pcheckpoint one can create checkpoints that are specially targeted to protect against single node and multiple node failures or possibly to provide protection to specific system-resources shared by multiple units such as PSU or potentially even entire racks. Currently with MPI there is no support from the programming model for implementing fault tolerant algorithms. The best one can do is to ensure that a nice error message is printed upon failure. For pcheckpoint to have any practical relevance other than a proof-of-concept, a distributed-memory application programming interface with some form of support to fault tolerance is needed. A proposed extension to MPI is currently under development called User-Level Failure Mitigation. ULFM adds to MPI the capability to detect failures and repair broken communicators whilst maintaining the extreme level of performance that the various implementations of MPI typically provide. A prototype implementation already exists with OpenMPI that may be used by application and library developers to experiment with these features.
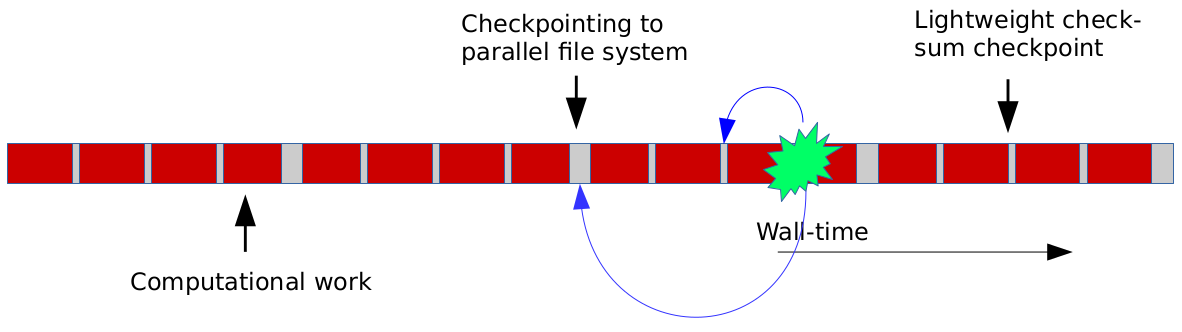
Many scientific codes involve the simulation of how some initial state evolve over time and thus share a similar overall structure, this in turn suggest that the code needed to make such applications fault tolerant trough multi level checkpointing will share many similarities. Figure 2 outlines the general concept of multi-level checkpointing. In addition to using pcheckpoint for efficient protections and recovery of data, for a fault tolerant applications one would also need to write code that instructs the application on how and when to use spare-ranks, how and when to update the content of checkpoints, how to recover and restart upon failure, this including repairing data structures on ranks that replace lost ranks. Using ULFM we're developing an interface called Llama to sit between the pcheckpoint library and the user. Llama abstracts away most of the complexities mentioned here. It provides a simple and easy-to-use interface for enabling applications to recover automatically and continue in the face of single and multi-node failures. Central to the use of Llama is the notion of guard objects and checkpoint objects. In the beginning of the parallel application that one wishes to make fault tolerant, one must declare a guard object. The Llama-guard takes care of the following tasks
- Maintaining the pool of worker and spare ranks
- Keeping track of which arrays that needs to be protected
- Keeping track of the status of all checkpoints
- Monitoring the application status and initiate recovery if necessary
- Choosing which checkpoint to recover from when a failure is detected
The user must then notify the guard of all arrays that must be protected as well as declare a checkpoint object for each type of checkpoint needed. In addition to declaring a llama::guard and some checkpoints, the user must write a function that specify how a newly enrolled spare rank may commence work given access to the data recovered from the failed rank. The hope is that this interface will abstract away the internals of data protection and recovery so to make it fairly simple to make highly fault tolerant applications whilst still being sufficiently flexible that it may be used for a wide range of time-stepping applications. The library is still under development, we hope to be able to release the code for the community to use in the near future.

