
Author: Michael Bareford, EPCC
Nektar++ [1] is an open-source MPI-based spectral element code that combines the accuracy of spectral methods with the geometric flexibility of finite elements, specifically, hp-version FEM. Nektar++ was initially developed by Imperial College London and is one of the ExaFLOW co-design applications being actively developed by the consortium. It supports several scalable solvers for many sets of partial differential equations, from (in)compressible Navier-Stokes to the bidomain model of cardiac electrophysiology. The test case named in the title is a simulation of the blood flow through an aorta using the unsteady diffusion equations with a continuous Galerkin projection [2]. This is a small and well-understood problem used as a benchmark to enable understanding of the I/O performance of this code. The results of this work lead to improved I/O efficiency for the ExaFLOW use cases.
The aorta dataset is a mesh of a pair of intercostal arterial branches in the descending aorta, as described by Cantwell et al. [1], see supplementary material S6 therein. The original aortic mesh contained approximately sixty thousand elements, prisms and tetrahedra. However, the tests discussed in this report use a more refined version of this dataset, one that features curved elements of aorta. The test case itself is run using the advection-diffusion-reaction solver (ADRSolver) to simulate mass transport. We executed the test case for a range of node counts, 2n, where n is in the range 1 - 8 on ARCHER [3] in order to generate the various checkpoint files that could then be used by a specially written IO benchmarker.
This tool, called FieldIOBenchmarker [4], was written to better understand the performance costs associated with reading and writing checkpoint field files - it uses the Nektar++ FieldIO class, which was subclassed for each IO method covered by this report: specifically, XML, HDF5 and SIONlib. The first of these approaches (XML) maintains individual checkpoint files for each MPI process, which inevitably results in weak performance due to disk contention as one increases the number of cores. HDF5 [5] is a hierarchical data format that allows parallel file access, hence all MPI processes can read and write to the same file; however, it is also necessary to explicitly record which parts of a HDF5 dataset belong to which MPI rank. The SIONlib library [6] on the other hand, records such details automatically, removing the burden of file management from the application designer. The additional functionality required to manipulate HDF5 and SIONlib files was added to v4.2.0 of the Nektar++ code base.
A set of benchmark scaling runs was performed in order to record how the time taken to execute FieldIO::Import and FieldIO::Write varies with the number of cores. Both routines were called ten times for each core count, allowing an average value for execution time to be plotted. The FieldIOBenchmarker tool takes a parameter that specifies how many tests are to be performed. Setting this parameter to ten can lead to caching effects that result in fast file access times; to counter this departure from realistic test conditions, the test count parameter was set to one and FieldIOBenchmarker was instead called ten times from within the submission script.
The average import times reveal that HDF5 yields the quickest reads except for the highest core count (3072), where XML and SIONlib both achieve faster times. When it comes to writing checkpoint files, SIONlib is consistently out-performed by XML and HDF5. Note, for core counts of 1536 and 3072, some of the IO methods show considerable variation: closer inspection of the results confirms that this variation is due to one or two test runs being much slower.
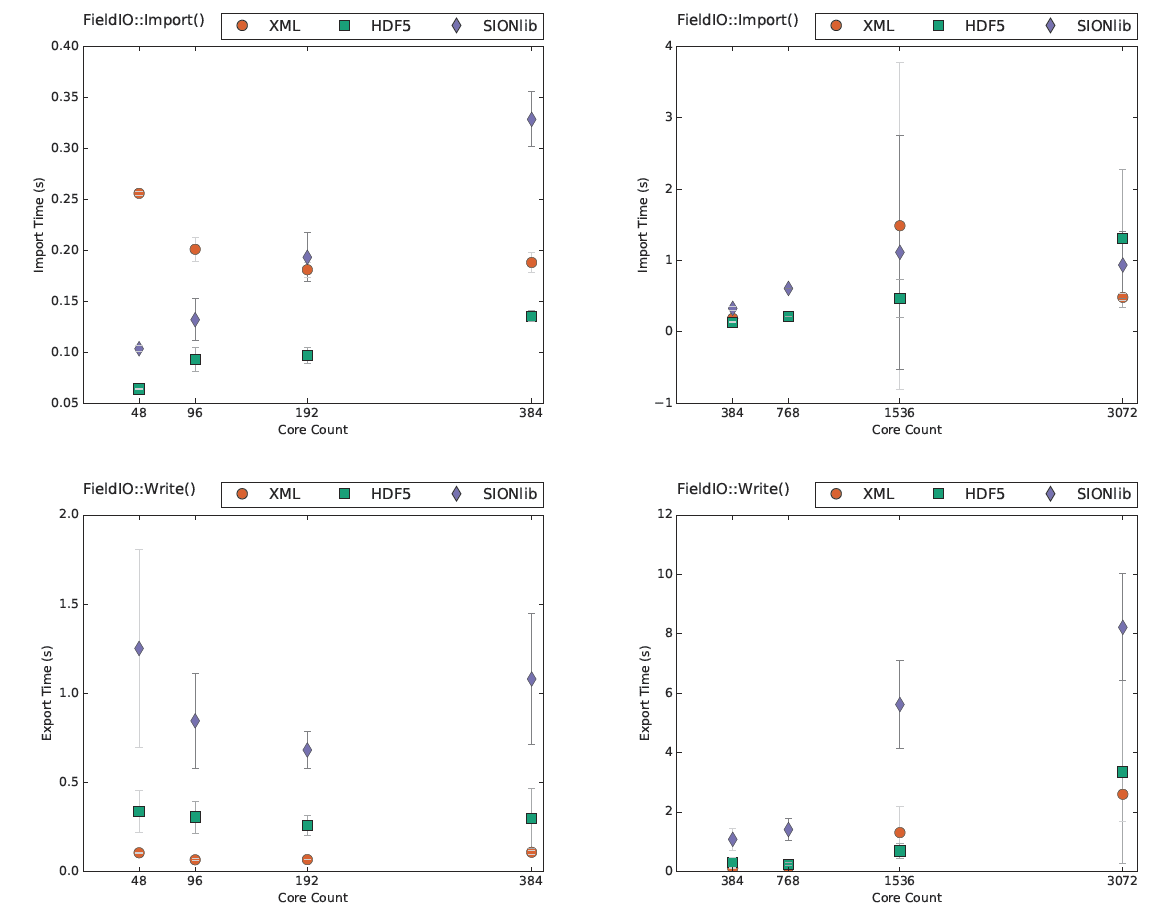
Figure1: Scaling plots of average time spent in FieldIO::Import (top row) and FieldIO::Write (bottom row) routines. The plots are displayed with deviation bars.
For the single checkpoint file methods, a rising core count creates greater decompositional overhead. Furthermore, the amount of data handled by the HDF5 import increases dramatically with core count due to a simple implementation detail concerning the FieldIOHdf5::Import routine: all MPI processes read the entire decomposition and element ID datasets. This means it should at least be possible to improve the HDF5 import times for the case where the number of MPI processes is unchanged from when the checkpoint was written. Each MPI process should be able to import the elements originally assigned by reading the decomposition dataset, i.e., it should not be necessary to also read in the entire element IDs dataset.
Improving the performance of an IO method requires one to know where time is being spent (or wasted). This type of analysis is best achieved with flame graphs. Figure 2 presents two flame graphs, one that shows the call tree stemming from the XML Import function, whereas the other is based on FieldIOXml::Write. The root function is represented by the widest box that runs along the x-axis - the inclusive time spent in the root function is normalised to 1. The widths of all the other boxes are based on this normalised time. Any traced functions that were called by the root function are shown as boxes placed immediately above the root function box and so on. Note, there is no particular significance in the colour chosen for each box or in the box’s starting coordinate (i.e., left most edge) - those properties are set so as to aid visual clarity. Some of the boxes have been labelled so as to identify the function, e.g. “2: Nektar::LibUtilities::FieldIOHdf5::ImportFieldData(1.0) - 0.5”. The first number is the level within the stack trace; the number in brackets at the end of the function name is the average number of calls to that function for all MPI processes; and the last number is the average normalised time spent in the function. The XML write calltree (Figure 2, bottom) reveals that a large portion of time is spent in MPI barrier calls, this supports the findings of Nash et al. [4], who found that the time to write a checkpoint file increased markedly with core count.
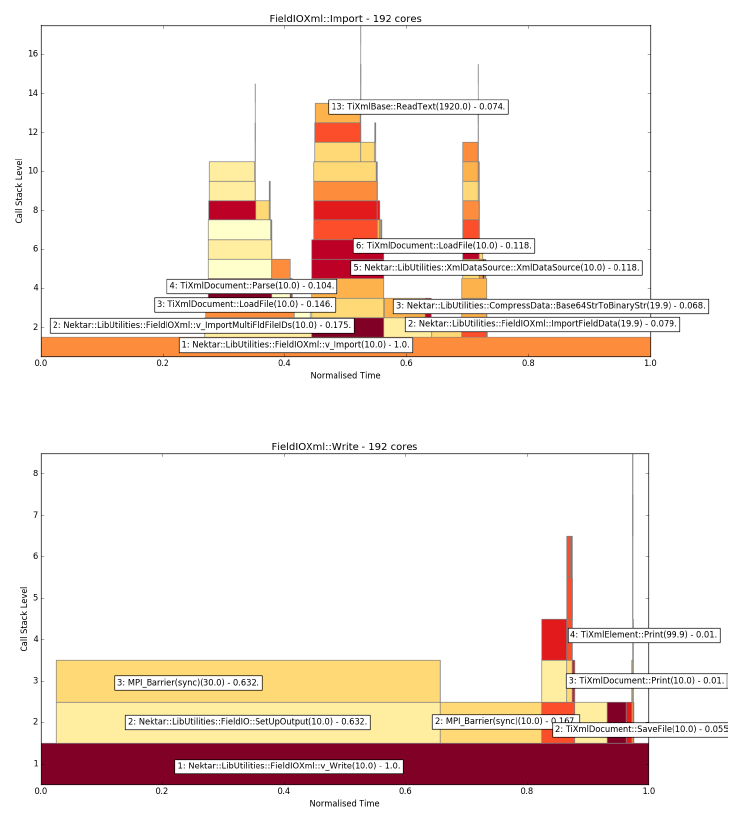
Figure 2: Flame graph produced by FieldIOBenchmarker using XML method over 192 cores (8 ARCHER nodes) for ten import tests (top) and ten write tests (bottom)
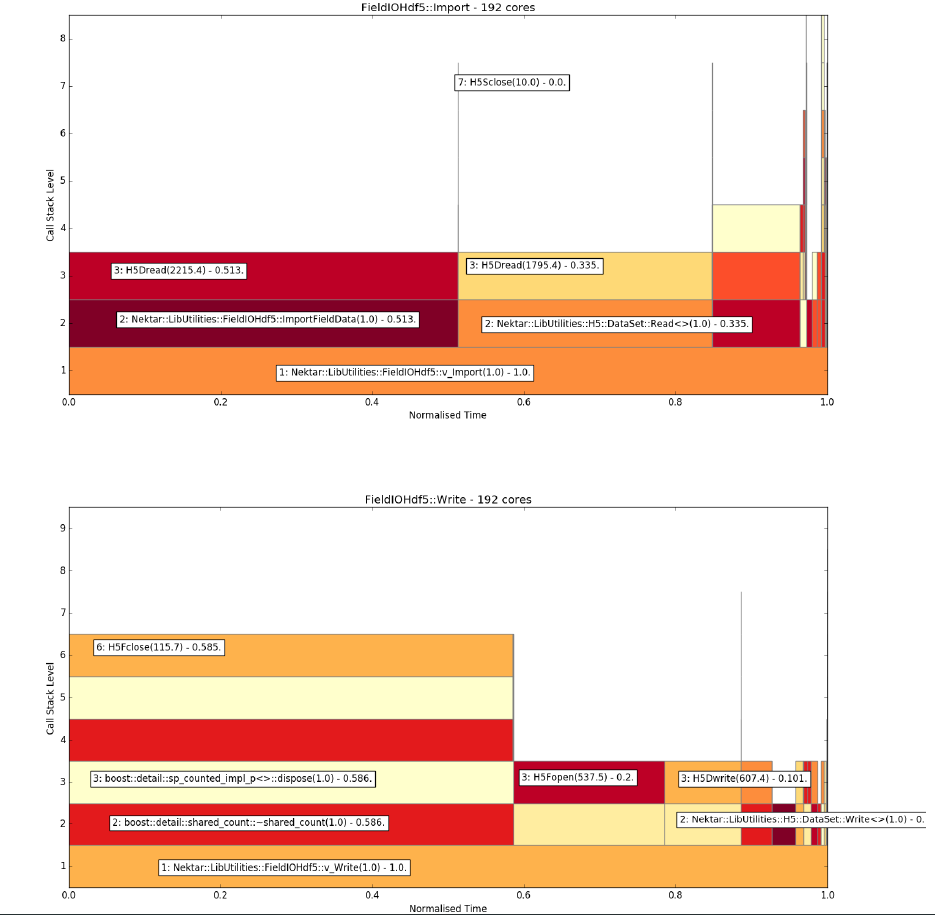
Figure 3. Flame graph produced by FieldIOBenchmarker using HDF5 method over 192 cores (8 ARCHER nodes) for one import test (top) and one write test (bottom).
The overall finding of this report is that HDF5 should be considered as a replacement for XML. HDF5 performance is at least comparable to XML, which means that any improvements to the HDF5 implementation are likely to make HDF5 the best-performing IO method of the three discussed here. Figure 3 (bottom) clearly identifies one area where a substantial gain could be made: the time taken to close the checkpoint file as part of the write function. HDF5 also has the important advantage of using just one checkpoint file, making it easier to prevent large Nektar++ runs from exceeding file count quotas.
For more information in regards the contents of this article you can contact Michael Bareford of EPCC at This email address is being protected from spambots. You need JavaScript enabled to view it. or read a related paper publication here.
REFERENCES
[1] C. Cantwell, D. Moxey, A. Comerford, A. Bolis, and G. R. et al., “Nektar++: An open-source spectral/hp element framework,” Computer Physics Communications, vol. 192, pp. 205–219, July 2015.
[2] P. E. Vincent, A. M. Plata, A. A. E. Hunt, P. D. Weinberg, and S. J. Sherwin, “Blood flow in the rabbit aortic arch and descending thoracic aorta,” Journal of The Royal Society Interface, vol. 8, pp. 1708–1719, May 2011. [Online]. Available: http://rsif.royalsocietypublishing.org/content/8/65/1708
[3] EPCC. (2015) Archer user guide. Web site. [Online]. Available: http://www.archer.ac.uk/documentation/user-guide/
[4] R. Nash, S. Clifford, C. Cantwell, D. Moxey, and S. Sherwin, “Communication and i/0 masking for increasing the performance of nektar++,” Edinburgh Parallel Computing Centre, Embedded CSE eCSE02-13, May 2016. [Online]. Available: https://www.archer.ac.uk/community/eCSE/eCSE02-13/eCSE02-13-TechnicalReport.pdf
[5] HDF5, HDF5 User’s Guide, release 1.10.0 ed. University of Illinois, USA: The HDF Group, March 2016. [Online]. Available: https://support.hdfgroup.org/HDF5/doc/UG/HDF5_Users_Guide.pdf
[6] J. S. C. (JSC). (2016) Sionlib v1.6.2 - scalable i/o library for parallel access to task-local files. Web site. [Online]. Available: https://apps.fz-juelich.de/jsc/sionlib/docu/index.html
[7] C. Inc., Using Cray Performance Measurement and Analysis Tools, s-2376-60 ed. Seattle, WA, USA: Cray Inc., September 2012. [Online]. Available: http://docs.cray.com/books/S-2376-60/

