Author: Allan Nielsen, EPFL
This year, the 25th ACM International Symposium on High Performance Parallel and Distributed Computing was held in Kyoto, May 31st to June 4th. ExaFLOW was represented by EPFL with a contribution to the Fault Tolerance for HPC at eXtreme Scale Workshop. At the workshop, Fumiyoshi Shoji, Director of the Operations and Computer Technologies Division at RIKEN AIC, delivered an exciting keynote talk on their K-computer and its failures. EPFL and ExaFLOW contributed to the workshop with a talk on Fault Tolerance in the Parareal Method.
![]()
What's "Parareal" you may ask.
Parareal is a technique to enable parallel-in-time integration of time-dependent system of PDEs. In the strong scaling limit, achievable parallel speed-up by the use of classical spatial domain decomposition methods tends to saturate for a large number of cores. Parareal can be thought of as a method to introducing domain-decomposition in time, thereby extending parallel scalability. At EPFL MCSS, a great deal of expertise exists on Parareal which has the potential to extend scalability to millions of cores. This particular algorithm is comparatively simple from the view-point of fault-tolerance, thus being an excellent platform for investigating various fault-tolerance strategies. Furthermore, its structure is close to that of a point-iterative methods and therefore offers insight into a larger class of general iterative methods.
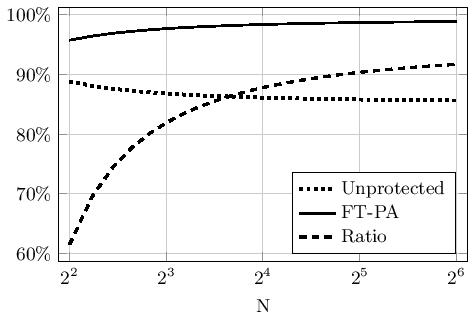
At the workshop in Kyoto, we presented a forward type recovery model in which nodes asynchronously detect when adjacent nodes have failed and identify available spare nodes. As long as spare nodes are available, the algorithm may recover. The modified fault-tolerant algorithm was implemented using ULFM MPI. Experiments confirmed that the new algorithm “survives” >90% of the errors that would otherwise have resulted in an execution failure. This is obtained with very little overhead both in fault-free execution and in recovery. You can take a look at the conference proceedings for the math details here.
Moving forward, we're using the experience gathered to develop fault-tolerance capabilities in Nektar++. For Nektar++ we are implementing a checkpoint-restart recovery approach where, upon failure, spare nodes automatically take the place of lost nodes, hence allowing the application to resume from nearest check-point without a system wide restart. For scalability, we are developing a multi-layer checkpoint approach, supplementing classic to-disk checkpoints with inexpensive “diskless checksum checkpoints” that may be sampled more frequently. At these checkpoints, all critical data is compressed as a checksum that is stored diskless on spare-nodes. This checkpoint process is much faster, yet allows for the application to recover as long as the number of lost nodes is small. The loss of a small subset of nodes constitute the bulk of all failures, so the expectation is that this approach will prove highly scalable.
If you'd like to know more on our ongoing work with implementing diskless checksum checkpointing in Nektar++, do not hesitate to get in touch with Chris Cantwell (ICL) or Allan Nielsen (EPFL). Stay tuned for more updates on ExaFLOW resilience!