

Das STEDG Projekt im Detail
Themen |
Ausgangslage und Ziele des Vorhabens
Ausgangslage
Die numerische Simulation von Strömungen ist eine unverzichtbare Methode für Forschung und Entwicklung in allen Ingenieurbereichen. Sie wurde zu einer Schlüsseltechnologie für die Verbesserung der Wirtschaftlichkeit, Umweltverträglichkeit und Sicherheit und trägt entscheidend zur Wettbewerbsfähigkeit der deutschen Industrie bei. Allerdings gründet sie sich häufig noch auf vereinfachte Methoden, um unter den vorgegebenen zulässigen Rechenzeiten zu Ergebnissen zu kommen. Die Berechnung turbulenter Strömungen um Realkonfigurationen beispielsweise basiert im Allgemeinen immer noch auf den Reynolds-gemittelten Navier-Stokes Gleichungen (Reynolds-averaged Navier-Stokes (RANS)), wobei die turbulenten Vorgänge durch algebraische oder Ein- bzw. Zwei-Gleichungs-Modelle modelliert werden. Es werden somit in der Regel Verfahren angewandt, die in der Zeit gemittelte stationäre Lösungen liefern. Für viele reale Industrieanwendungen spielen jedoch die zeitabhängigen Phänomene durchaus eine wichtige Rolle und die RANS Lösungen sind unzureichend. Zwar werden in den Forschungs- und Entwicklungsabteilungen erste Berechnungen, zum Beispiel basierend auf Large-Eddy-Simulationen (LES), ausgeführt, es werden dazu aber kommerzielle Programmpakete eingesetzt - mit numerischen Methoden, die für die herkömmlichen stationären Simulationen mit Turbulenzmodellen geeignet sind und ein breites Anwendungsspektrum haben, für instationäre Vorgänge aber viel zu rechenzeitintensiv sind. Eine effiziente Simulation instationärer Vorgänge mit höherwertiger Turbulenzmodellierung bedingt aber eine umfassende Erneuerung aller Komponenten: Numerische Methoden und Algorithmen und deren effiziente Implementierung auf modernen Hardware-Architekturen.
Während an neuen numerischen Methoden international in verschiedenen Arbeitsgruppen intensiv gearbeitet wird, bleiben die Änderungen in der Hardware der einzusetzenden künftigen Rechnergenerationen noch weitgehend unberücksichtigt. Die neuen Entwicklungen in der Hardware-Architektur der Hochleistungsrechner verlangen drastische Änderungen in den Programmiermodellen der Simulationscodes, um diese Architekturen auch effizient nutzen zu können. Dies muss von einem Paradigmenwechsel im Verständnis der Nutzer begleitet werden: Während Nutzer in der Vergangenheit davon ausgehen konnten, dass die Leistungsfähigkeit der Simulationen direkt mit der Leistungsfähigkeit der Rechner steigt, ist dies in Zukunft in dieser Art nicht mehr der Fall. Die Leistungsfähigkeit der Systeme steigt nicht wesentlich mehr dadurch, dass die einzelnen Prozessoren schneller werden, sondern durch die Verwendung von immer mehr Prozessoren. Dies gilt sowohl in Bezug auf die Knoten, deren Zahl immer höher wird, als auch der Cores innerhalb eines Knotens. Künftige Architekturen werden Systeme von Shared Memory Knoten sein, wovon Anwendungscodes derzeit kaum Gebrauch machen. Auch die weiter aufgehende Schere von Prozessor-Leistung zu Memory-Bandbreite ist auf User-Conferenzen kaum Thema.
Dieses Projekt adressiert die Änderungen, welche die Softwareentwicklung aufgreifen muss, um mit den Entwicklungen der Hardware Schritt zu halten. Es werden hochaktuelle, neuartige numerische Methoden, die von ihrer Struktur her genau auf diese Rechner-Architektur passen, zu effizienten Werkzeugen in der Strömungssimulation weiterentwickelt. Dabei geht es einerseits um die numerischen Methoden und Algorithmen der Zukunft als auch deren Mapping auf die Hardware-Architekturen von heute (multi-core) und morgen (many-core Architekturen). Es werden reale Anwendungen aus der industriellen Forschung und Entwicklung (F+E) betrachtet und deren heutige Umsetzungsmöglichkeiten mit den aktuellen und zukünftigen Entwicklungen korreliert
Ziele
Dieses Projekt betrachtet die gesamte Software-Entwicklung zur numerischen Simulation instationärer Strömungen aus komplexen Anwendungen. Zukunftsträchtige Algorithmen für Probleme, die sich auch heute noch der numerischen Simulation entziehen, werden so implementiert, dass sie auf den zukünftigen Hardware-Architekturen effizient laufen. Die Simulation realer Anwendungen mit höherwertiger Turbulenzmodellierung wird durch die Kombination neuer numerischer Methoden mit effizienter Implementierung auf modernen Hardware-Architekturen erst ermöglicht. Die Leistungskraft dieses Ansatzes wird exemplarisch an aktuellen Problemen der Anwendung aufgezeigt, die von den Industriepartnern als Prototypen definiert werden. Kurz: es geht um die numerischen Methoden der Zukunft, effizient implementiert auf den Architekturen der Zukunft, angewandt auf die industriellen Probleme und Fragestellungen der Zukunft.
Die Ziele des Projekts beinhalten:
- Numerische Modellierung turbulenter Strömungen mit zeitgenauen numerischen Verfahren.
- Methoden zur Analyse und Optimierung der Rechen-Codes mit Anpassung an Hierarchien in der Hardware-Architektur in Bezug auf Netzwerk und/oder Memory.
- Verbesserung der Skalierbarkeit der Algorithmen innerhalb wie zwischen den Knoten.
- Evaluierung und Bestimmung von Cost-Faktoren für ein optimiertes Load-Balancing der in Raum, Zeit und Genauigkeitsordnung hoch-adaptiven Verfahren.
- Auswertung und Validierung anhand industrie-relevanter großer Testfälle, die bislang nicht oder nicht in akzeptablen Turn-Around-Zeiten berechenbar sind.
Es werden hochwertige Turbulenzmodellierungen, die auf dem Konzept der Grobstruktursimulation beruhen, zur Beschreibung komplexer Strömungsprobleme herangezogen. Die numerischen Methoden sind auf instationäre Strömungen abgestimmt und erlauben eine explizite Zeitdiskretisierung, was zur Reduktion der Rechenzeit, aber auch zu wesentlich reduziertem Kommunikationsaufwand zwischen parallelen Prozessen führt. Durch Verwendung von hochlokalen Verfahren mit einem minimalen Datenaustausch mit Nachbarelementen sollte die Anwendung auf den neuen Rechnerarchitekturen hervorragend skalieren. Dadurch wird es möglich, industrielle Anwendungen in vertretbaren Zeitspannen zu simulieren und Probleme zu berechnen, welche sich bislang einer numerischen Simulation versagen.
Ein Prototyp eines solchen Problems ist der Einspritzvorgang bei gasgetriebenen Motoren. Hier tritt das Gas als Überschallstrahl in das Einspritzrohr ein, wird dort von der Querströmung abgelenkt und trifft auf die Rohrwand unter Wechselwirkung mit reflektierten Druckwellen. Die numerische Simulation des gesamten Vorgangs mit Aussagen über Lärmentwicklung und Lärmreduktion ist eine zentrale Anwendung in diesem Projekt. Bislang lassen sich nur Teilaspekte in der Forschung simulieren mit einem Rechenaufwand von über 10.000 CPUh, was für den systematischen Einsatz im Design-Prozess zu hoch ist. Eine zweite Problemstellung betrifft die Analyse der Aerodynamik und Aeroakustik einer Hochauftriebskonfiguration bei Flugzeugen. Wird eine vollkommen dreidimensionale Fragestellung betrachtet, die durch einen hybriden Fluidmechanik/Akustik Ansatz gelöst wird, benötigen Rechengitter ca. 5 ⋅ 108 Zellen, entsprechend hoch ist der Memory- und Rechenzeitbedarf. Die dritte Anwendung ist die Düsenoptimierung beim Laserstrahlschneiden, bei der eine komplexe Überschallströmung mit Verdichtungsstößen in einer sehr komplexen Geometrie auftritt. Hier ist nicht so sehr die Turbulenz das entscheidende Problem, sondern die Auflösung der auftretenden Verdichtungsstöße und die komplexe Geometrie mit Schneidkopf und Schnittspalt.
Um die Rechenzeiten von der mehrwöchigen Ebene auf mehrere Tage zu senken, sind HPC-Architekturen unbedingt notwendig. Die aktuellen Architekturen werden dabei dominiert von Dual- und Quad-Core Architekturen. In naher Zukunft ist mit 8, 16, 32 Cores pro Knoten zu rechnen, in absehbarer Zeit mit 100 oder mehr. Der Einsatz dieser Many-Core Prozessoren für Cluster-Systeme wird zu Systemen mit Tausenden von (u.U. heterogenen) Cores führen. Die Progammier-, insbesondere die Parallelisierungsmodelle werden in diesem Projekt der Entwicklung angepasst, um die hohe Parallelität zu strukturieren und nutzbar zu machen. Dies führt insbesondere in Bezug auf den Arbeitsspeicher und die Memory-Hierarchien zu Herausforderungen, die von den Simulationswerkzeugen aufgenommen werden müssen, um wegen der Schere zwischen Prozessorleistung und Memory-Bandbreite die Performance der Simulationen nicht zu reduzieren.
Innovationen durch dieses Projekt: Numerik von morgen auf Rechnerarchitekturen von morgen in der Anwendung
Hochgenaue numerische Verfahren in komplexen Geometrien
Es werden zwei unterschiedliche numerische Methoden für die Simulationen eingesetzt. Neu entwickelte Discontinuous-Galerkin-Verfahren (DG-Verfahren) kombinieren die einfache Ordnungserhöhung von Finite-Elemente-Verfahren mit der Möglichkeit der Auflösung starker Gradienten. Ein DG-Verfahren im Raum-Zeit-Bereich bietet die Möglichkeit, auf ein lokal stark unterschiedliches Verhalten der Strömung durch lokale Gitter-Verfeinerungen und lokale Genauigkeitserhöhung in Raum und Zeit in Kombination mit lokalen Zeitschritten zu antworten. Damit wird die Effizienz des Verfahrens auch auf sehr unregelmäßigen Gittern gewährleistet. Dies ist eine völlig neue Eigenschaft, die den wesentlichen Nachteil von expliziten Verfahren auf unstrukturierten Gittern beseitigt. Neben dem DG-Verfahren wird ein Finite-Volumen-Ansatz (FV) betrachtet, mit dem detaillierte Erfahrungen am AIA bei Grobstruktursimulationen vorliegen. Dies umfasst sowohl den Bereich der Randbedingungsformulierung, die hier in der Grobstruktursimulation eine erhebliche Rolle spielt, als auch der physikalischen Darstellung des Strömungsproblems. Die Untersuchung zweier numerischer Ansätze ist angebracht, um Effizienzvergleiche und die Validierung der Ergebnisse durchzuführen. Auch für die Steuerung der lokalen Genauigkeitsordnung bei DG-Verfahren und deren Verhalten in höherwertigen Turbulenzmodellen liegt wenig Erfahrung vor. Ein Vergleich mit einer robusten Methode, für die viel Erfahrung vorliegt, ist dabei unerlässlich.
Mapping der Algorithmen auf heutige und künftige Rechner-Architekturen
Heutige Simulationscodes sind nur unzureichend auf die Anforderungen der neuen Architekturen vorbereitet. Parallelisierung bedeutet momentan üblicherweise MPI-Parallelisierung, vom innerhalb des Knotens verfügbaren Shared Memory wird kein Gebrauch gemacht, auch die geichzeitige Ausführung unterschiedlicher Programmteile bei eingefrorenen Bedingungen findet sich selten in Anwendungscodes. Ein wichtiger Schritt, um die Effizienz von Simulationscodes auf Shared Memory-Architekturen zu erhöhen, ist die hybride MPI/OpenMP Parallelisierung. Der zweite wichtige Schritt ist die Analyse und Optimierung der Kommunikation zwischen den Knoten. In Abhängigkeit der verfügbaren Interconnects (Infiniband, Gigabit-Ethernet, Myrinet, direkter hierarchischer Interconnect, ...), aber auch der zu kommunizierenden Datenmenge muss die jeweils günstigste Implementierung der Kommunikation gewählt werden. Die von der Universität Houston, Texas, und dem HLRS entwickelte Bibliothek „Abstract Data and Communication Library“ (ADCL) ermöglicht die automatisierte Auswahl der für den konkreten Anwendungsfall optimalen MPI-Kommunikation auf der jeweils vorgegebenen Maschine. Damit wird den Anwendern eine transparente Methode zur Verfügung gestellt, um zur Laufzeit für wechselnde Anwendungsfälle mit jeweils unterschiedlichen Datenmengen und somit unterschiedlichen Kommunikationsanforderungen die jeweils effizienteste Kommunikation zwischen den Knoten zu ermitteln und zu verwenden. Dadurch wird auch bei Ausführung des Codes in wechselnden Umgebungen, beispielsweise kleine und mittlere Testcases auf dem Institutscluster, mittlere bis große Testfälle in der HPC-Umgebung des HLRS, automatisch die für diese Kombination von Testfall und Architektur, optimale MPI-Routine verwendet.
Dynamische Lastverteilung
Je höher die Anzahl der für einen Rechenlauf verwendeten Knoten ist, desto wahrscheinlicher sind Ausfälle zur Laufzeit oder Imbalancen in der Performance der Knoten, sei es durch Fehler, sei es durch heterogene oder hierarchische Konfiguration der Maschine. Umgekehrt erzeugt ein adaptiver Code, der sich dynamisch an die Lösungsanforderungen anpasst, selbst Imbalancen, indem in einem Bereich mehr Gitterzellen entstehen oder eine höhere Verfahrensordnung gewählt wird als in anderen. Eine dynamische Lastbalancierung zur Laufzeit ist daher dringend erforderlich. Durch die hohe Lokalität nicht nur im Raum-, sondern auch in der Zeitapproximation des am IAG entwickelten Verfahrens ist die Numerik in der Lage, sehr flexibel auf Änderungen zu reagieren und Imbalancen zur Laufzeit auszugleichen. Dies setzt allerdings Kriterien voraus, die bei Bedarf eine Umverteilung der Rechengebiete (Domain Decomposition) oder eine Erhöhung der Verfahrensgenauigkeit (h-p Adaptivität) initiieren. Hierfür werden Cost-Faktoren bestimmt, die derzeit noch teils heuristisch, teils bereits durch Performance-Messungen zur Laufzeit ermittelt werden. Numerik und Performance-Analyse können so zur Laufzeit interagieren und die aktuelle Simulation optimal anpassen. Dafür ist es wichtig, den Nutzern geeignete Tools und Umgebungen zur Verfügung zu stellen. Die Instrumentierung der Codes und Analyse auftretender Ereignisse und Muster darf keine neuen Hürden aufbauen. Ziel des Projektes ist daher auch der Wissenstransfer bzgl. Performance-Analyse-Tools in die Nutzer-Community sowohl der universitären Forschung als auch der industriellen F&E.
Ingenieurprobleme als Herausforderungen der Simulation auf Höchstleistungsrechnern:
1. Das Problem der Gasinjektion
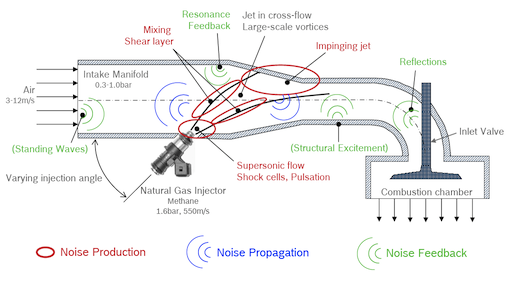
Geräuschentstehung bei der Gasinjektion
Die Bedeutung gasführender Düsen und Ventile bei mittleren und hohen Drücken nimmt durch die verstärkte Einführung von Fahrzeugen zu, die mit alternativen Kraftstoffen, wie z.B. komprimiertem Erdgas oder Wasserstoff betrieben werden. Dabei spielt die Geräuschentstehung von Injektor- und Ventilströmungen bei hohen Druckdifferenzen und somit i.d.R. überkritischen Machzahlen eine große Rolle. Aktuell in der Industrie eingesetzte kommerzielle Strömungstools können jedoch bislang keine zufrieden stellenden Aussagen oder Tendenzen im Rahmen des Produktentwicklungsprozesses liefern, da deren zugrunde liegende numerische Methoden die komplexe Aufgabenstellung nicht effizient und genau genug lösen können. Ziel im Rahmen dieses Projekts ist die direkte akustische Simulation des Gasinjektionsproblems. Es umfasst die instationäre Überschallströmung des Gasstrahls mit Turbulenz und akustischen Quellen, die nichtlineare und lineare Schallausbreitung im Bereich des Strahls und ins Fernfeld, Wechselwirkungen und Reflektionen mit der Umgebung und schließlich die Rückwirkung der Akustik auf die Strahlströmung. Eine deutliche Reduktion des Simulationsaufwandes für ein solches Problem würde Sensitivitäten numerisch vorhersagbar machen und damit die geräuscharme Auslegung von Düsen und Ventilen bereits im Entwurfsprozess ermöglichen.
2. Dreidimensionale Hochauftriebskonfigurationen bei Flugzeugen

Strömungsfeld um Hochauftriebshilfen
Die Lärmerzeugung und Lärmabstrahlung während Start und Landung wird zukünftig noch stärker im Mittelpunkt stehen, wenn die Umweltverträglichkeit neuer Flugzeuge diskutiert wird. Bei der Landung machen neben dem Fahrwerk die Hochauftriebshilfen einen wesentlichen Anteil des Lärmpegels aus. Während die Erzeugung und Abstrahlung des durch den Slat bedingten Lärms auf einer quasi-2D Basis analysiert worden ist, müssen im nächsten Schritt auch die Halterungen des Slats in die Untersuchung miteinbezogen werden, da sie maßgeblich den Lärmhaushalt mitbestimmen. Die Wechselwirkung der im Cove-Bereich des Slats, an den Hinterkanten und durch die Halterung erzeugten Scherschichten bedingt eine extrem komplexe Strömungsstruktur. Die detaillierte Erfassung dieses Strömungsfeldes erwartet eine höherwertige Turbulenzmodellierung. Diese zu akzeptablen Turn-Around-Zeiten einsetzbar zu machen, ist das Ziel der in diesem Projekt angestrebten Entwicklungen. Dies bedeutet Auswahl und Adaption der Verfahren Hand in Hand mit der Implementierung und Optimierung unter Berücksichtigung der Hardware-Eigenschaften.
3. Optimierung der Gasführung in einem Laserschneidkopf
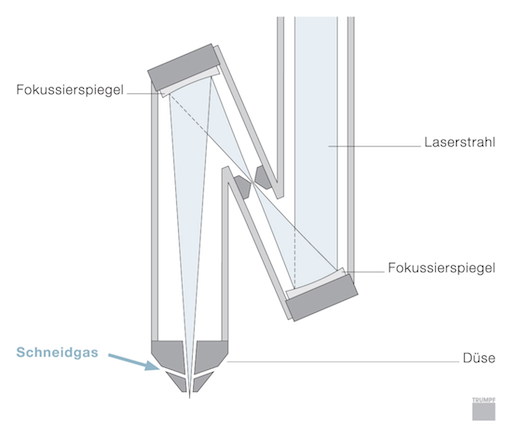
Ein Spiegelschneidkopf
Beim Laserstrahlschneiden wird mit Hilfe eines Lasers das Werkstück in dem Bereich des Laserfokus aufgeschmolzen und mit einem Gasstrahl aus dem Schnittspalt ausgetrieben. Die vom Markt geforderte Erhöhung der Schneidgeschwindigkeit und die damit einhergehenden Entwicklung von Schneidlasern höherer Leistungen erfordert ein neues Schneidkopfkonzept, bei welchem die heute verwendeten Lochdüsen durch wesentlich komplexere Ringspaltdüsen ersetzt werden. Experimentelle Untersuchungen zeigen, dass geringfügige Änderungen an der Geometrie der Ringspaltdüse, welche den Gasstrahl formt, einen großen Einfluss auf das Schnittergebnis haben können. Mit den heutigen Simulations-Tools ist es jedoch noch nicht gelungen, die sich ausbildende Überschallströmung mit komplexen und nicht stabilen Stoßsystemen genau genug zu berechnen und damit die wesentlichen Einflussfaktoren der Düsengeometrie auf die Schneidgasströmung und die Lärmentstehung herauszuarbeiten. Für die Qualität beim Schmelzschneiden sind auch die sich an der Blechunterkante ausbildenden Wirbel wichtig, da diese Sauerstoff aus der Umgebung an die heiße Schnittfront transportieren und diese dann oxidiert. Ziel der Simulation wäre es, schon in der Entwurfsphase einer Düse Rückschlüsse auf ihre Schneideignung ziehen zu können und somit wichtige Erkenntnisse schon im Designprozess zu liefern. Neben der komplexen Geometrie ist hier das Auftreten von starken Stößen eine große Herausforderung an die numerische Simulation.