n3d is a CFD (computational fluid dynamics) simulation code designed for investigating wake effects and other turbulent flow features for wind turbines. Turbulence, and wake effects, can have significant impacts on the power that a wind farm can generate for any particular wind condition, so accurately simulating these wind flow features can help to optimize the layout of wind farms and the designs of wind turbine configurations.
Figure 1: The NEXTGenIO systemn3d utilises a method that involves the integration of the full three-dimensional Navier-Stokes (NS) equation and the adjoint equation iteratively. However, to undertake the adjoint approach the full direct numerical simulation (DNS) output is required, necessitating storage and reading/writing of very large amounts of data. An average simulation could easily require 30 Terabytes (TB) of data to be stored between the algorithmic phases, with larger simulations generating hundreds of TB of intermediate data, even at a moderate Reynolds number several orders smaller than the real one. This represents both a large requirement on storage capacity for HPC systems, and a large cost in terms of the time required to first write this data during the forward phase of the simulation (the DNS part), and then read that data back in again for the inverse (adjoint) part of the simulation workflow.
I/O, reading and writing data to permanent storage systems, such as disk drives, is a lot slower than manipulating data in a computer’s memory, or undertaking calculations on the processor itself. Depending on the hardware that is available it can be thousands of times slower to read some data from storage as it would be to generate that data using instructions on the processor. Therefore, whilst the adjoint approach does allow efficient simulation techniques to be utilised, and high fidelity simulations to be undertaken, addressing this I/O bottleneck is important in ensuring that the simulations are as efficient as possible, and the HPC systems running the simulations are utilised effectively.
Part of the HPCWE work is investigating data reduction techniques to shrink the amount of data that has to be written and read for this computational workflow. However, we are also investigating using high performance I/O hardware for this task as well. EPCC, at The University of Edinburgh, has a prototype HPC system that has non-volatile memory within each of the compute nodes, that offers very high I/O performance for applications. This prototype system, developed within the EC funded NEXTGenIO project, has 34 compute nodes, each with 48 processing cores, and 3TB of non-volatile memory.
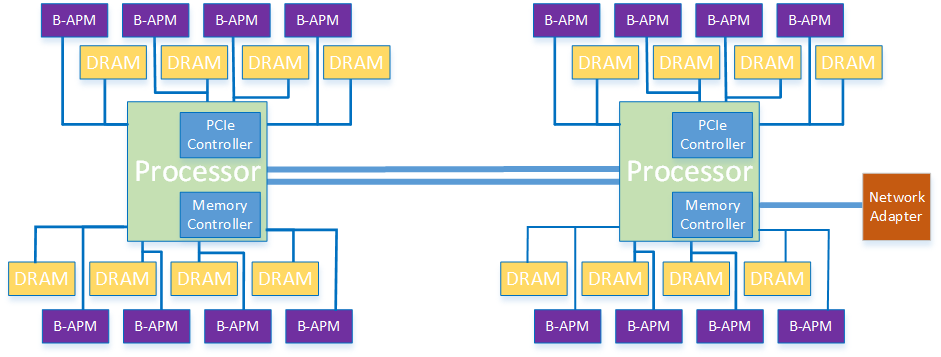
We have ported the n3d application to this prototype system and adjusted its functionality to utilise this in-node storage capability for the transfer of data between the forward and adjoint phases of the simulation. This involved re-writing some of the I/O functionality to target this optimised hardware directly, and providing some functionality to manage the data during and after the application runs. Figure 2: Compute node configuration with the non-volatile memory (B-APM) connected with the volatile memory (DRAM) to the processors’ memory controllerWe benchmarked the n3d application with a range of different test cases, one that requires only 8 processes to run and generates 600MB of data for the adjoint phase (the small benchmark), one that requires 72 processes to run and generates around 6TB of data (the medium benchmark), and one that requires 512 processes to run and generates around 40TB of data (the large benchmark).
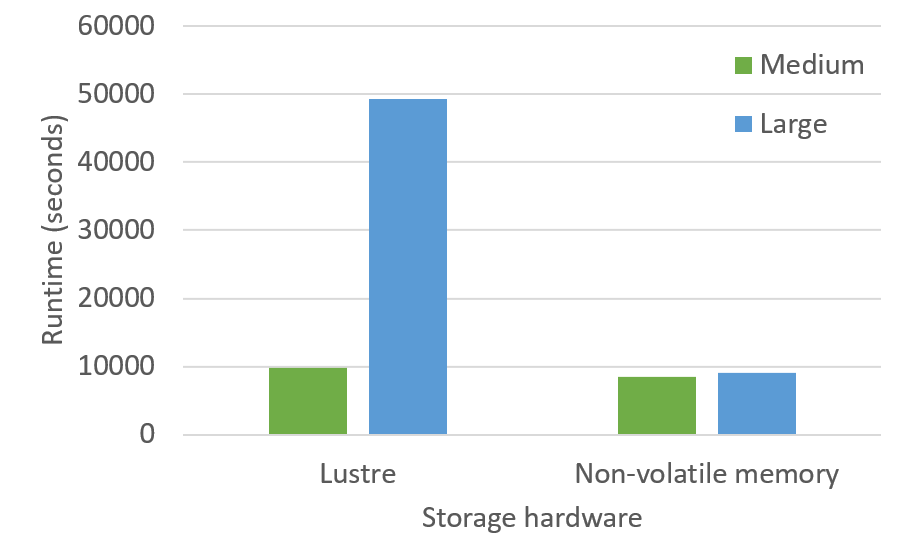
For the small benchmark, there was no noticeable benefit from using the non-volatile memory for transferring data between the different algorithmic phases. I/O was not a significant performance bottleneck for this benchmark configuration. However, when moving to the medium and large benchmarks we observed very significant performance improvements using this new memory technology, with around a 15% runtime reduction for the medium case, and an over 80% runtime reduction for the large case.
Figure 3: Performance of Lustre vs non-volatile memory for the medium and large benchmark cases. Total runtime of the application is reported.
– Adrian Jackson, Senior Research Fellow, EPCC, The University of Edinburgh
Manage Cookie Consent
We use cookies to optimize our website and our service.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.