About S(o)OS
News
Downloads
Links
Lounge


Functional Hardware Specifications


{jcomments on}As we move from homogenous multi-core to heterogeneous many-core processors, with no standard architecture in sight, we are faced with a large problem of programming these devices. Even if all the cores would be homogenous, Amdahl’s law dictates that these cores should be asymmetric, with a small number of “big” but fast cores and a large amount of “small” but slow cores. The “big” cores handle those parts of the program that are inherently sequential, while the “small” cores execute the concurrent parts of the program in parallel. This paradigm shift not only places a huge burden on the application developer, who will most likely have to ensure that parts of his program run concurrently if he wants to get any type of performance on these new processors. Developers of operating systems, run-time systems and compilers now have to cater for a multitude of potential targets the applications will run on. As there is no foreseeable standard architecture (i.e. IA32) for these new many-core systems, it is likely that the heterogeneity of cores, the number of cores, and the symmetry between homogenous cores will vary from processor to processor for the time being.
An operating system in charge of running applications on such a many-core system, or a compiler to compile for such a platform, will have to be provided with information concerning the capabilities of the available cores. Note that such a compiler should not be thought of as a single program that is executed on the workstation of the application developer. Instead, it will be a system of programs that run on both the end-user’s machine (e.g. JIT compiler for a specific core) and on the workstation of the developer (e.g. a program that outputs LLVM code). The operating system and compilation platform are of course interested in different aspects of the eventual hardware. The compiler/run-time system might be interested in the vector width of a core to determine granularity of the data-parallel execution of a certain thread, that is, if the available data-level concurrency can be exploited with a single core or not. The operating system might be interested if a core has extra capabilities to efficiently support task-level parallelism; to determine if it can schedule a new thread on a core that is already running a thread, or if it should execute the new thread on another core.
Higher-order functional specifications
We propose a specification language that captures the general structure of a multi/many-core system in which functional and non-functional properties of both the cores and the interconnect, relevant for the execution of applications, can be captured. A strongly typed, higher-order functional/declarative language seems well suited for such a purpose. Before we continue with what we believe are the merits of using such a type of language, we first give an example of the type of specifications we have in mind:intel48 = meshLayout 6 4 routerN mapping
where
mapping x = [ pentium3 (x*10 + lbl) | lbl <- [0. .1] ]
The code above specifies Intel’s latest 48-core System-on-Chip (SoC), which has 24 routers connected as a mesh, and where 2 Pentium3’s are connected to each router. The meshLayout function has 4 arguments: the width of the mesh network, the height of the mesh network, the type of router for each node in the mesh, and a mapping. The mapping argument is a function that specifies the number and type of cores connected to each router, so given a router label, it returns a list of cores (in the above case two cores for each router). The graph that can be (automatically) inferred from the above specification is depicted in Figure 1, where the routers are drawn as circles and the cores as squares.
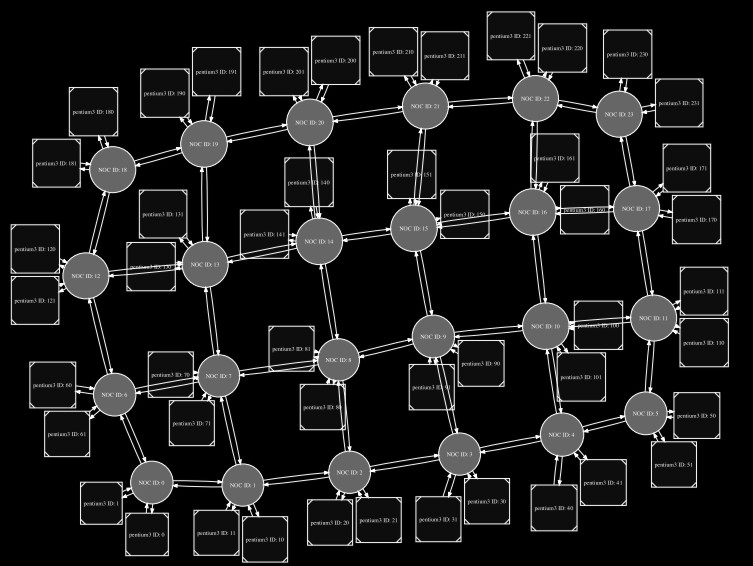
Figure 1
Just as easily we can make a specification for the Cell Broadband Engine (CelIBE), by using the rinqLayout function and a mapping for one PowerPC and 8 SPU’s:cellBE = ringLayout 9 ringR mapping
where
mapping 0 = [ powerPC 0 ]
mapping x = [ spu X ]
In this example, the mapping function indicates that the PowerPC is connected to the router with label 0, and that a SPU is connected to any other router.
Both the meshLayout function and the ringLayout function are special instantiations of the more general layout function which takes as arguments: the structure of the network, a set of routers, and a mapping function which binds a router to (zero or more) processor cores. It falls outside the scope of this abstract to give the precise definition of the layout function.
We will just illustrate the use of the layout function by making a description of Intel’s Core i7, where every Nehalem core is connected to all the other cores through a QPI link (See Figure 2 for the, again automatically, inferred graph):
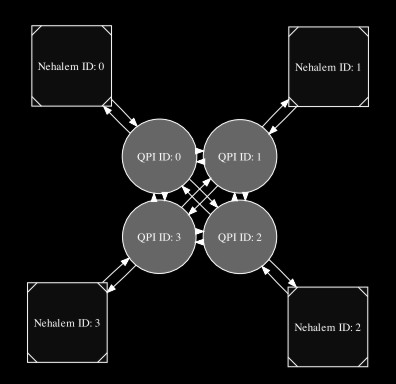
Figure 2
corei7 = layout (connected 4) qpi mapping
where
mapping x = [ Cpu Nehalem” x j
connected n = [ filter (/=z) [0.. (n-1)] | z <- [0.. (n-1)] ]
qpi = Router “QPI”
Although these examples are in no way a complete specifications of the actual processors, they should however give some indication of the level of conciseness that can be achieved by using a higher-order declarative language to specify both the structure of, and the signal flows within, the hardware.
We propose a typing system that goes further than just specifying the interfaces of the components, and include information that is relevant to the compiler, run-time system, and/or operating system. The reason that we want to encode this information in the types of both the cores and interconnect, is that we can separate functional properties from the structure of the hardware.
For example, we might want to explicitly encode in the type of the core that it is an 8-issue wide vector machine, with a 14-stage pipeline. Likewise we might want to specify the number of cycles it takes to perform a context switch (when the operating system wants to schedule another thread on that core). Or we can specify that the core can execute 4 threads at once, indicating that the core has the capabilities to exploit task-level parallelism.
Note that the above does not exclude the specifications of the non-functional properties of the hardware, such as the latency within the interconnect. As properties such as end-to-end delay between cores both depend on the structure and (non-)functional of both the interconnect and the cores, such information will have to be derived from the specification.
Related Work
Although declarative languages have been used to specify hardware in the past, as far as the authors know they have not been used to specify the hardware at such a high abstraction level with the intent of aiding in the optimized compilation and execution of application. Functional hardware description languages such as Lava (Bjesse, et al. 1998), ForSyDe (Sander and Jantsch 2004), and ClaSH (Baaij, et al. 2010) allow designers to specify (higher-order) structural specifications that can both be simulated and translated to synthesizable VHDL. The level of abstraction of these language is however much lower than needed for the descriptions proposed in this document, nor are they designed to aid in the optimized execution and compilation of applications on future many-core processors.
[1] Baaij, Christiaan, Matthijs Kooijman, Jan Kuper, Arjan Boeijink, and Marco Gerards. “ClaSH: Structural Descriptions of Synchronous Hardware using Haskell.” Proceedings of the 13th EUROMICRO Conference on Digital System Design, Architectures, Methods and Tools, September 2010: To appear.
[2] Bjesse, Per, Koen Claessen, Mary Sheeran, and Satnam Singh. “Lava: hardware design in Haskell.” Proceedings of the third ACM SIGPLAN international conference on Functional programming, 1998: 174-184.
[3] Sander, Ingo, and Axel Jantsch. “System Modeling and Transformational Design Refinement in ForSyDe. IEEE Transactions on Computer-Aided Design of integrated Circuits and Systems 23 (January 2004): 17-32.