About S(o)OS
News
Downloads
Links
Lounge


S(o)OS Deliverables
The Next Generation of Operating Systems


{jcomments on}Modern day operating systems have evolved as a means to support end-users and developers in their daily tasks without having to cope with the architectural details of the underlying resources. With the growing demand for functionality and the growing scope of resource types, the operating system thus has grown to become a large, and mostly inflexible platform for which to change is almost impossible by now: for example, n Windows 7 it took 6000 lines of code just to remove the dispatcher lock [1]. The execution costs for such complex systems were typically compensated by the development of faster and stronger processor generations.
With the introduction of multi-core systems, this assumption no longer holds true and effectively the whole OS environment has changed to a system that prefers the small, fit, and adaptable to the large and strong. This is grounded on two major development trends: scale and heterogeneity. In order to still provide powerful services, even though the underlying hardware will not increase in clock rate anymore, the system will have to be able to actually exploit the infrastructure and all its specifics. Non-regarding the similarity between current supercomputer cluster architectures and future multi-core desktop systems (scale, interconnect, topology etc.), the same techniques for dealing with the scale cannot be easily applied: desktop usage implies multiple applications running concurrently at the same time, as well as a higher degree of interactivity between users and applications. Furthermore, whilst time and effort can be vested into adapting programs and operating system for respective High Performance Computing usage, desktop systems must be able to deal with any type of infrastructure and show high portability – that’s actually one of the major objectives behind the original development of the Microsoft Windows OS: to hide the complexity of the underlying infrastructure and to allow for easy portability of the applications. Future operating systems must respect these aspects for the purpose of uptake and usability.
In order to deal with future infrastructures, operating systems particularly have to face the following issues:
- Scale: the amount of actual compute units will increase exponentially over the next few years. Whilst most systems have been developed to scale up to a certain degree, extending the scalability typically is achieved in a step-wise manner (i.e. increasing the factor by say 10) rather than trying to address a more general scaling model. This is simply due to the fact that such fundamental changes would require according effort in restructuring the program.
- Heterogeneity: since processors do no longer offer higher performance in the sense of clock-rate, an increasing demand for specialised units that can execute dedicated tasks efficiently, rather than being “generally usable”. Accordingly, systems grow in their heterogeneity to compensate the lack of general purpose execution speed, which however means that (software) integration becomes more and more complex and programs less and less portable.
- Latency: not only is delay a critical factor in any code execution that makes use of external resources, it is even more critical for distributed applications that have to communicate with one another. Since parallelism in future applications has to increase, latency may be a critical factor that actually slows down the effective execution performance.
- Cache Size: as performance of code becomes more relevant with no increment in clock rate compensating the respective needs, efficient memory management grows in importance. Cache misses are the biggest source for latency induced delays and the ratio of cache size to code size will always be smaller than 1.
- Concurrency: as opposed to dedicated high-end machines that effectively only execute one application at a time, most common usage will consist of multiple applications competing over shared (and limited) resources in the machine. Whilst pseudo-parallel execution does not pose (too many) issues for single-threaded processes, dealing with scalable processes in a concurrent fashion leads to serious synchronisation issues (see below)
- Coherency: distributed processes implies distributed state and memory – since most distributed applications assume that some form of shared memory is available, maintaining coherency between state and data is a time-critical task that leads to performance issues or the risk of instability. With the increasing scale of multi-core systems, maintenance of coherency becomes exponentially time-consuming.
- Synchronisation: in a concurrent, heterogeneous, large-scale environment, there is no way of guaranteeing synchronous execution. Accordingly, most distribution approaches implement a message queue that allows for asynchronous communication, which however implies that individual threads may have to wait for specific messages, thus delaying execution time.
- Centralisation / Bottleneck: the simplest approach towards dealing with distributed system consists in a centralised control mechanism (typically the Operating System), which takes the responsibility for scheduling, coherency and synchronisation tasks. With increasing scale, any centralised instance becomes a serious bottleneck and single point of failure though.
 Current operating system architectures cannot deal with these issues, making them impractical for future infrastructure environments. The classical trend to “evolve” the OS with the infrastructure does not work anymore, as the processor architecture has taken a different route down the development road than what the OS architectures were planned for. Accordingly, a completely new architecture is needed that is flexible enough to follow this new path. One currently proposed approach to this thereby consists in replication of the operating system, e.g. by using multiple instances of so-called “multi-kernels” [1]. Most approaches do not really support distributed programs and, more critically, cannot deal with a non-homogeneous processor architecture.
Current operating system architectures cannot deal with these issues, making them impractical for future infrastructure environments. The classical trend to “evolve” the OS with the infrastructure does not work anymore, as the processor architecture has taken a different route down the development road than what the OS architectures were planned for. Accordingly, a completely new architecture is needed that is flexible enough to follow this new path. One currently proposed approach to this thereby consists in replication of the operating system, e.g. by using multiple instances of so-called “multi-kernels” [1]. Most approaches do not really support distributed programs and, more critically, cannot deal with a non-homogeneous processor architecture.
In the S(o)OS (Service-oriented Operating Systems) project we pursue an approach that bases roughly on the concepts of Service Oriented Architectures and Grids to tackle this problem: self-managed modular microkernels [2]. In order to deal with scale and heterogeneity the operating system itself must adapt and spread out across the infrastructure. The main point for future execution support thereby does not so much consist in providing a single virtual system (i.e. exposing a virtual infrastructure that pretends to be a single-core environment with virtual high clock rate) as future applications will exploit parallelism and no means of automatic parallelisation can achieve sensible efficiency rates. Instead, the operating system must follow along the same principles as before: exposing a seemingly homogeneous infrastructure, so that developers do not have to cater for the individual hardware specifics. Just like with nowadays OS, the developer should nonetheless have the possibility to access and use hardware details, if need be.
Similar to the multi-kernel approach, S(o)OS spreads out across the infrastructure, but not by replicating the full operating system, thus obliterating the cache, but by instantiating so-called kernel “modules” which can be adapted to the respective resource’s characteristics and therefore support local execution according to the specific hardware. Individual cores therefore do not host a full operating system but only the functionalities that are needed for the execution of the respective processes / threads – by making use of standardised communication interfaces, these modules can be easily replaced and adapted similar to device drivers, yet with less impact on the whole system upon failures.
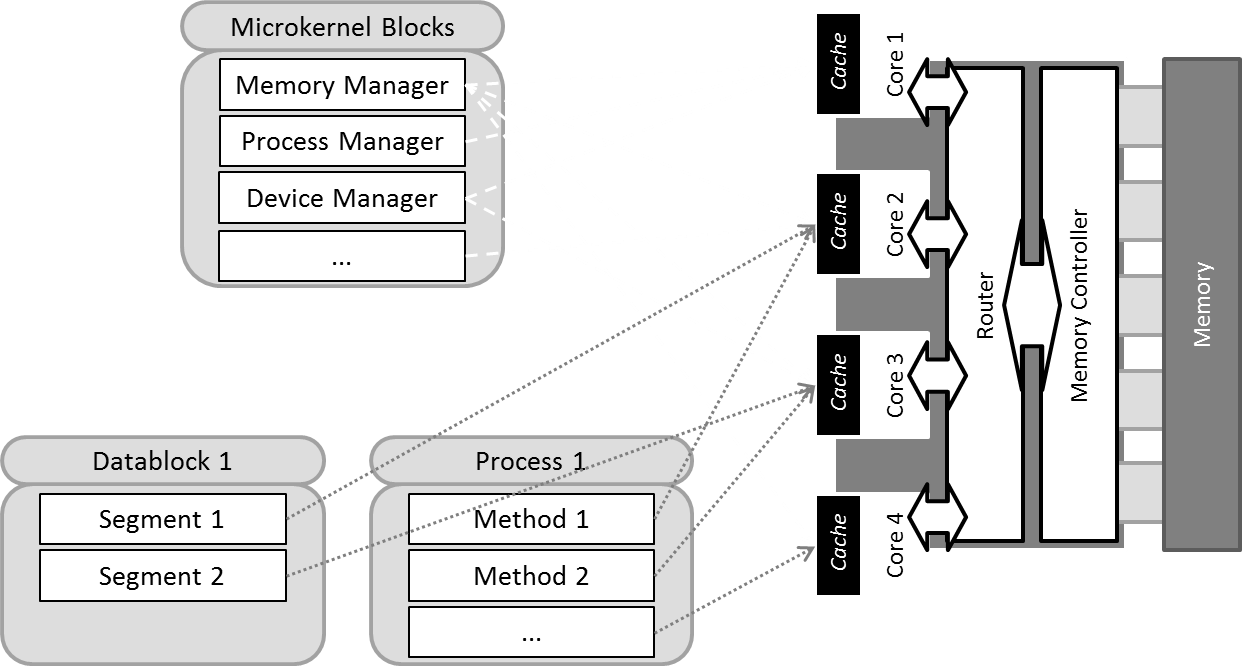
Most parallel applications improve execution speed by performing part of the calculation on individual cores, thus the according requirements towards the system are principally identical, leading to synchronised bottlenecks for system calls in a centralised monolithic system. By analysing the program requirements either on code level or at runtime, the according modules can be made available directly to the thread, thus leading to less management overhead than in a centralised case. As Baumann et al. already showed, the according messaging overhead does not reduce the overall performance [1] as is typically claimed for Microkernels [3].
To this end, the operating system must be able to identify the application’s needs and map them to the executing infrastructure. Application segments and operating system are thereby treated as “services” that need to be deployed on fitting resources (grid and SOA aspect). As opposed to SOA and Grid, the middleware (or here OS) must thereby not only respect the resource capabilities and availability, but also the connectivity and sequence of the executing segments by applying graph matching algorithms. The granularity of dependencies thereby defines the degree of fine-tuning the system can apply to improve performance: if the segment size exceeds the cache size or is close to it, the operating system will have to deal with remote memory swap similar to centralised execution. Dependencies also define the message exchange between segments, thus less granularity leads to higher data exchange in order to prepare synchronisation, if no other means are used, which imply either higher developing effort (OpenMP, MPI) or performance loss (access on demand, consistency). On the other hand, increasing the granularity leads to processing and memory overhead, or at least according development complexity.
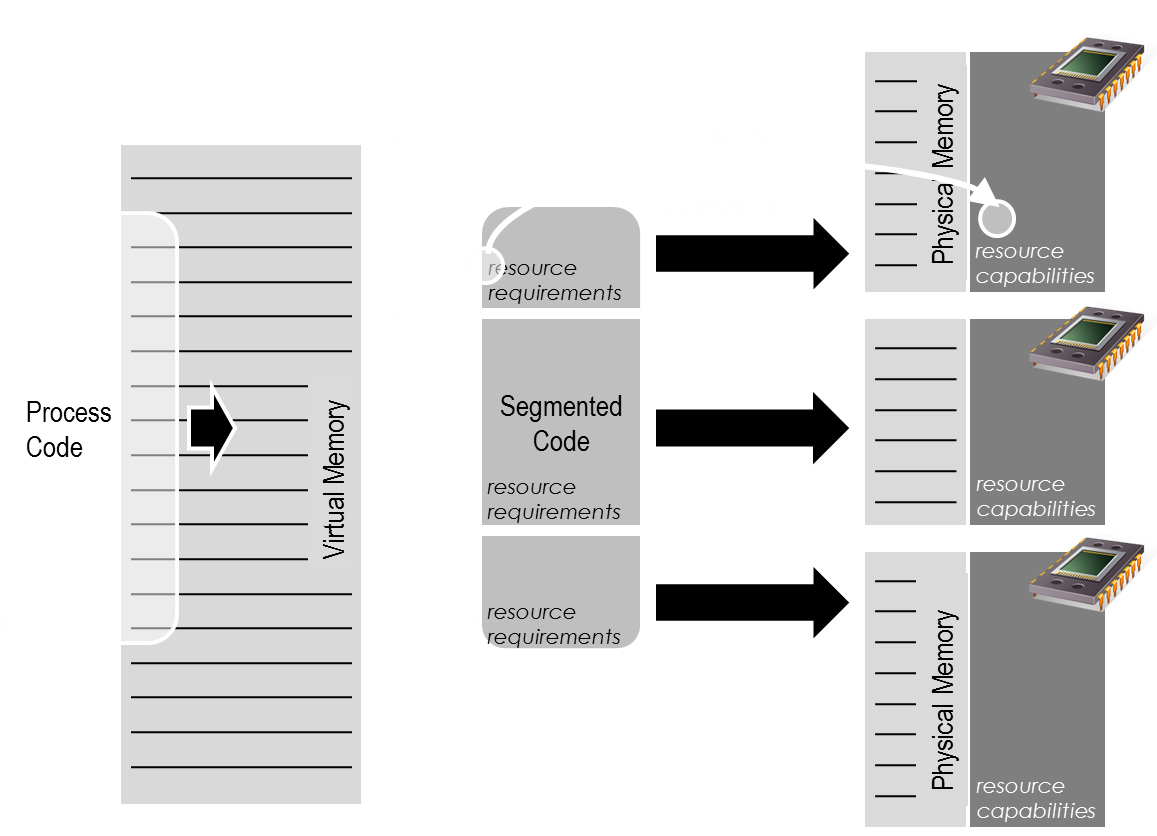
Whilst this approach allows dealing with scale, overcomes the bottleneck (as long as no singular external resources are requested concurrently), heterogeneity and cache size issues, it still poses problems with respect to synchronisation and coherency:
In a more or less completely distributed system, synchronisation cannot be controlled by a central instance, but the individual instances need to coordinate with each other as a form of implicit synchronisation. Since aside from these synchronisation points, the individual processes run effectively independently, this implicit synchronisation can be achieved in multiple ways, though again efficiency is in direct relationship to complexity. Most programming models currently define dedicated synchronisation points that block all threads – timesharing within such a blocked core would allow to make maximum usage of the compute unit whilst the thread is occupied waiting. The effective performance only improves over the total amount of applications though, and not over an individual one. The gain vs. loss of different synchronisation approaches are still being investigated in S(o)OS in the context of different usage scenario.
[1] Baumann, A., Barham, P., Dagand, P.-E., Harris, T., Isaacs, R., Peter, S. et al (2009). The multikernel: a new OS architecture for scalable multicore systems. In SOSP '09: Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles, pages 29-44. ACM
[2] Schubert, L., Wesner, S., Kipp, A., Arenas, A. (2009). Self-Managed Microkernels: From Clouds Towards Resource Fabrics. In CloudComp ’09: Proceedings of the First International Conference on Cloud Computing, Munich.
[3] Lameter, C. (2007). Extreme High Performance Computing or Why Microkernels Suck. In: Proceedings of the Linux Symposium, Vol. 1.