Project News
One Interface For Them All

Modern IT infrastructures constantly increase in scale, heterogeneity and complexity. With the introduction of the many core processor, even the average personal computer has been turned into a parallel machine, thus giving rise to a complete new computing paradigm - yet we still treat computers like a single von Neumann instance.

The heterogenity and complexity of modern IT infrastructures is constantly increasing - this does not only apply to the internet and modern data / cloud centers, but also to modern cluster systems and even personal computers: with multi- and even many-core technologies, as well as accelerators and GPU programming, any computer essentially incorporates multiple processing units that can in principle be individually addressed and used. But it does not end with the processing units - modern systems also incorporate multiple different communication modes, strongly varying memory / storage hierarchies, varity of additional devices etc. With the opening of utility computing over the internet, this complexity has increased manyfold as principally tasks and data can be outsourced to remote computers, with an according penalty in access time (bandwidth and latency constraints).
Non-regarding all these changes, we still deal with computers as if they would be single, sequential processing units: since the proposition by Alan Turing, hardly any real changes in developing applications have been made and all our programming models, software engineering concepts and even understanding of machines is oriented towards a single processor. By incorporating tricks, such as communication mechanisms and synchronisation points, we overcome this issue at least partially, but at the cost of high development overhead. Effectively, a modern developer has to think in terms of multiple single-system applications that exchange information at dedicated points, with the according implications on communication overhead etc., so that in general the application requires a vast amount of restructuring in the first instance.
With the introduction of Web Services and Clouds, the interest in developing distributed applications has increased even further. Due to the communication constraints in these environments, the general approach here consists in orchestrated or workflow-based execution of effectively completely isolated applications.
This means that non-regarding all recent paradigm changes towards distributed computing, the according changes have not yet altered our way of perceiving and using computers.
Structural Deficiencies
The problem is thereby not restricted to the ways of programming distributed systems alone. In fact, even if a new way of developing distributed applications could be devised and found according support, there is no way it could be appropriately employed given the current setup of infrastructures. More specifically, the essential management mechanism in modern computers are essentially, too, oriented towards a single-core sequential processing model. Modern Operating Systems and execution frameworks all essentially deal with processes individually and treat the underlying resource infrastructure as a set of individual von Neumann processors, rather than an aggregated mesh of combined resources.
Modern frameworks have become very effective in compensating for all the structural differences between different systems and to expose a virtually uniform system to the user, i.e. independent of the actual hardware configuration. Operating Systems generally assume that there is sufficient memory and processing power for an oversized environment that is optimised towards task sharing on single processors, memory switching etc., i.e. towards handling multiple processes in a single-core environment. This view is however no longer correct with modern chip architectures, which completely break up the classical von Neumann architecture and essentially expose memory and processing units dispersed over the network on different hierarchies and with different connectitivities.
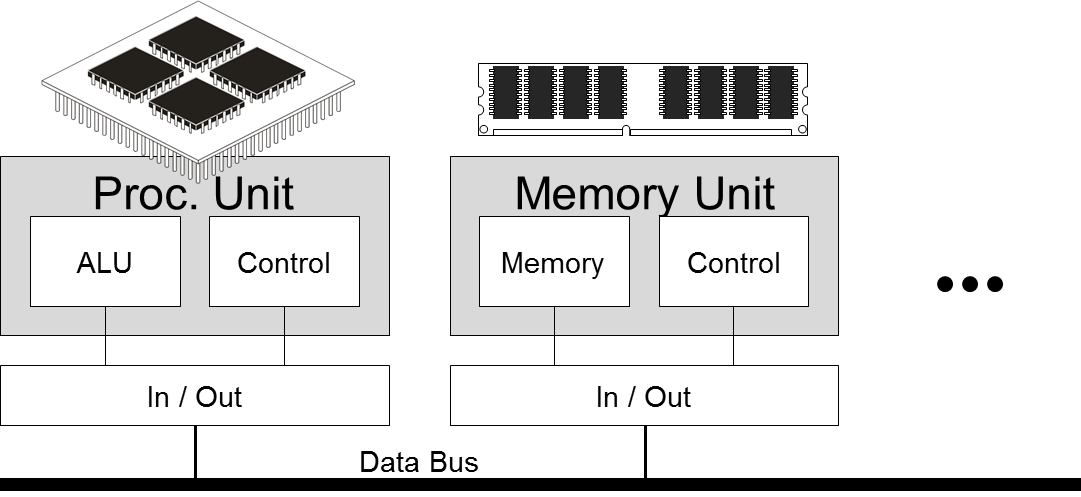
With these essential differences in architecture comes another major shift in the modern programming paradigm:
For the classical von Neumann machine, memory was basically co-located to the processing unit, thus making data easily accessible and available. As long as the processing units were slower in processing the data thus provided, it was a primary paradigm for all programming that "calculation is expensive and data is for free". Decades of elaboration in operating systems, programming models and compilers base on this model, making the compiler for example focus on storing and fetching intermediary data in order to save processing cost. With the new model, this no longer holds true, though: processing units are faster than memory access and due to the shared access to higher level caches in many-core processors, data processing is much faster than data provisioning. In other words, the new guiding principle is "calculation is free, communication expensive".
This has multiple implications on various levels. The monolithic organisation of an Operating System for example caters for memory management of the processes, but not of itself - due to the large structure it causes multiple cache misses for each system call, thus further overloading the available communication capacities. Similar our programming models focus on the execution of operations and disregard handling of data / memory. The data structure comes implicit with the functional choices and the developer can generally expect that his data, i.e. his variables are generally co-located with the code. These assumptions however are responsible for major execution performance losses in modern systems.
One Interface for Them All?
The general approach to dealing with the complexity of the underlying infrastructure consists in exposing a single interface that is supposed to integrate the systems underneath and cater for their respective capabilities, requirements and restrictions. This way the developer can create a program unconstrained by the details of the resource model underlying the interface, and thus increase the interoperability and portability of his code with little effort. It is up to the interface to map the code behaviour appropriately to the actual resources and so far, this approach worked fairly well. The virtual interface is thereby essentially identical to the compiler that converts the logic into executable code - implicitly, it is exposed to the developer as the programming model and / or the programming environment.
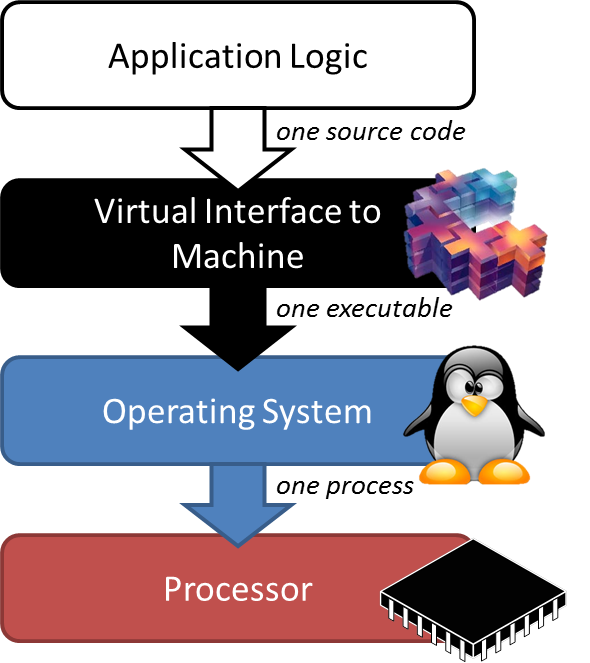
What if however the model of the program does not match the structure of the underlying resource environment?
Classically, the virtual interface matched the actual physical infrastructure in at least so far, as a single processor used to cater for the application logic. The different areas of distributed computing, i.e. High Performance Computing on the one hand and Web Service based workflows on the other, had to introduce different tricks and mechanisms to compensate for the mismatch. Essentially these tricks consist in splitting the application logic into multiple separate applications with different loads - in the case of the web service domains, these services can principally regarded as fully standalone applications, whereas in High Performance Computing these separate processes (threads) have only limited scope.
Notably, in the HPC case, the developer effectively still faces a single interface, namely the programming model, which is responsible for extracting the individual processes / threads according to the developer's directions. It is thereby assumed that each thread / process gets its complete own environment in terms of operating system, communication support, memory management etc. A developer can easily produce faults in his code this way, as he will implicitly expect linkage between the threads which is effectively very weak in the threads generated by the compiler. What is more, with the processes / threads actually being expected to be hosted in effectively their own environment, there is a high implicit risk of running out of sync, which can have desastruous effects if not account for by the developer.
As opposed to this, a workflow specifies all links between the applications explicitly and implies a timing behaviour that can intuitively be controlled by the developer. However, this approach not only suffers from its extreme slowness due to the coordination overhead, but also from the lack of timing control. Similar to the HPC case, the fact that the individual tasks are effectively executed independently of each other leads to a potential timing misalignment - in the workflow case this however is even worse to control as the unpredictability of the task behaviour (and hence execution time) increases with its complexity.
ADD PICTURE NON-MATCHING CONVERSION
With the introduction of multicore architectures, this situation gets even worse, as it introduces a mapping error on a second level: not only does the interface (compiler) have to convert the code into a set of seperately executing threads / processes / applications, but also management of the execution does not actually occur on this level. Instead, a set of processes will be hosted as a block on one processor, which in turn is managed by a monolithic operating system. The operating system then treats these threads as unlinked processes that compete over the resources and are principally unaware of the other sets on the other processors.
Though it is possible to exert some control on this behaviour and how the processes are deployed, this requires additional effort by the developer, taking the actual layout of the infrastructure, the different communication modes and potential timing deviations into account. If the infrastructure is potentially dynamic, respectively in order to introduce reliability, the effort on developer side increases manyfold.
Towards the Next Generation of Programming
It is hence essentially necessary to rework the whole development and operation stack, aligning the individual conversion steps more properly with one another. This starts from the architectural structure of the operating system to enable it to deal with a real distributed environment, rather than taking a centralistic stance that has to deal with all tasks (processes and threads) at the same time. This does not only require that management of the individual processes and threads is decoupled from one another, but also that this management support is reduced to an absolute minimum to reduce the overhead. This leads to multiple problem, in particular since even though the individual processes actually execute independently, they nontheless are linked to each other as described above, so that there is a high risk that management creates synchronisation overhead instead (or more correctly: in addition) to the communication overhead of the individual processes.
Therefore the application itself needs to be restructured in the first instance, providing additional information about its distribution and dependencies, in other words incorporating concepts of distribution from the beginning. The information must be sufficient to enable the conversion stack to create a really distributed application from this description. This means that the individual processes can execute in a mostly independent fashion with well-aligned synchronisation points being explicitly given by the programmer and/or implicitly inferred by the execution environment.
The S(o)OS project addresses the means to build up an operating system architecture that supports such a distributed application and its execution by integrating the means for maintaining communication and synchronisation across executing processes. The S(o)OS kernels are thereby explicitly designed to create a minimum in communication overhead and in memory usage. For more details on the S(o)OS architecture, please refer to the project website.
This newsletter primarily deals with the different aspects involved in realising true distribution in the source code level of the application, i.e. in the programming model itself.